Building systems in Microsoft Azure isn't as simple as building local applications.
Especially maintaining data consistency across services can become quite a challenge.
The main reasons it is hard to maintain data consistency in a distributed cloud environment are:
- The network may cause transient exceptions during write operations.
- The services may cause throttling and backpressure during write operations.
- Most services don't support transactions across entities, and definitly not across services.
How can you maintain data consistency then?
To ensure data consistency in a distributed system, without transactions, each unit of work must be atomic, retriable and idempotent
- Atomic: implies that each unit of work should perform only a single write operation at a time. This to avoid partial completion.
- Retriable: If that write operation would fail, due to transient exceptions, the unit of work must be retried until it succeeds.
- Idempotent: In case the unit of work gets retried, yet it did already succeed before, the outcome of the operation should still be the same.
Our recommended patterns have been carefully selected to collectively support building distributed systems with these properties in mind, while using the limited atomic capabilities that the Azure Platform has to offer.
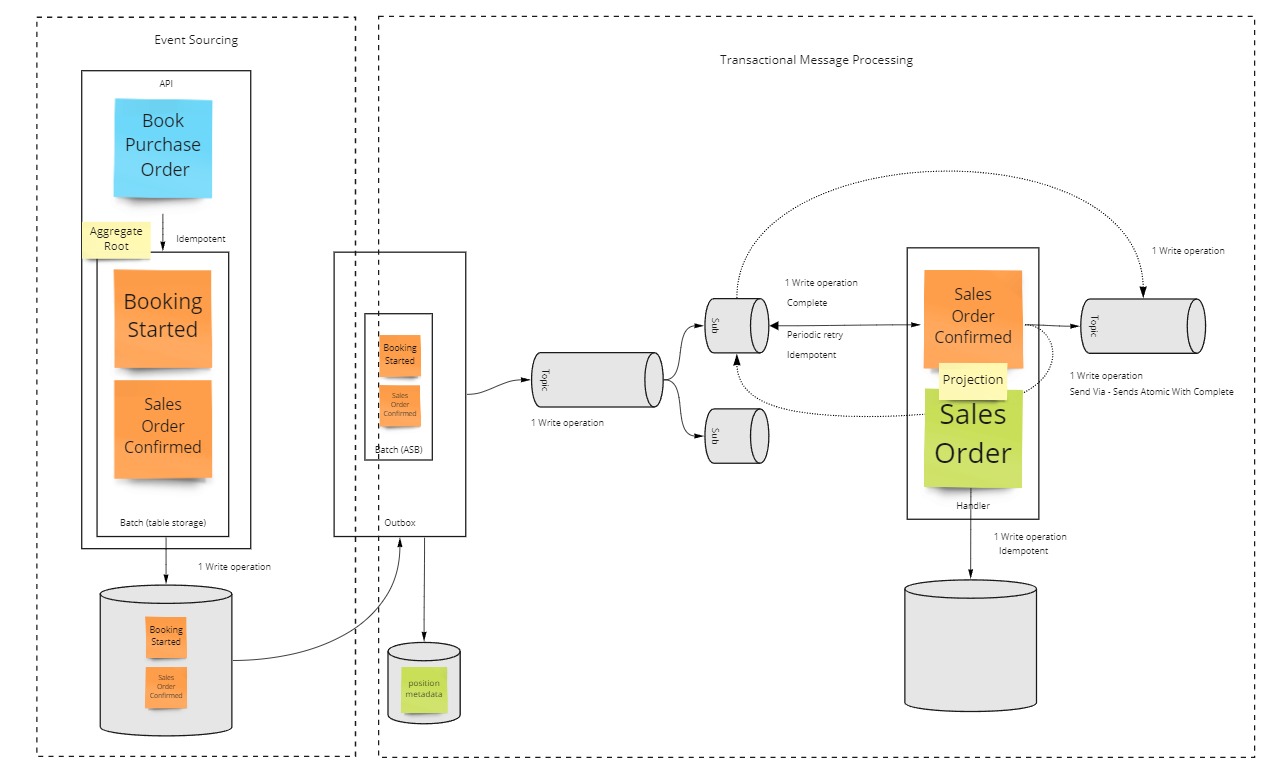
Event Sourced Aggregate Root
The first of the atomic patterns is the Event Sourced Aggregate Root.
It has the responsibility to decide how the system should respond to a command requested by a user.
The events emitted to capture these decissions, are written to an Azure Storage Table in a single operation, using a so called entity group transaction.
Outbox
As an extension to the event store, you can enable a message pump, called the outbox.
This outbox reads the events from the store and forwards them in a single operation to, e.g. an Azure Service Bus topic (or queue), in order to distribute the decissions across the system.
This pump does need to remember the position read from the event store, and as a consequence has to perform a second write operation.
Should either the first or second write operation fail, then the outbox will retry the send operation at a later point, ensuring at least once delivery of the messages.
Atomic message processing
To enable atomic processing of individual messages from a queue or topic, and support atomic handover to another queue or topic, we leverage the transfers and "send via" capabilities of Azure Service Bus.
Leveraging this capability, the MessageHandler atomic processing runtime can perform combine send operations as an atomic operation together with the complete operation performed on the received message, after successful processing.
Within this processing scope, represented by a handler, there is room to perform exactly one more write operation.
Should this operation fails, e.g. an exception is thrown, then the received message will be abandoned and retried.
In the case that the failing logic also sends out a message, to notify completion of the operation, this message could become a ghost message and lead to duplicates on the next try.
Using the "send-via" technique any ghost messages and duplicates will be prevented.
Projection
One of the most common operations performed in the scope of a handler is a projection.
A projection rolls up one or more events into a single state object.
This single state object can then be stored in a database of choice in a single operation without the need for transactions on the target data store.
This approach has the added benefit that you can use any database, storage, cache, big data or cognitive service available in azure and you don't have to limit yourselves to the ones that happen to be suitable to also act as an outbox at the same time.